사전 설정
build.gradle 의존성 추가
implementation 'org.springframework.boot:spring-boot-starter-aop'
implementation 'org.springframework.boot:spring-boot-starter-actuator'application-dev.yaml 설정 추가
server:
tomcat:
mbeanregistry:
enabled: true
management:
endpoints:
health:
show-details: always
web:
exposure:
include: *
병목 지점 디버깅용 Aspect 추가
Controller, Service , Repository Layer 각 함수 실행시간 로깅
@Aspect
@Component
@Slf4j
public class ExecutionTimeAspect {
@Pointcut("execution(* com.eighttoten.service..*(..)) ||"
+ "execution(* com.eighttoten.controller..*(..)) ||"
+ "execution(* com.eighttoten.repository..*(..)))")
public void businessLogicPointcut(){}
@Around("businessLogicPointcut()")
public Object loggingMethodExecutionTime(ProceedingJoinPoint joinPoint) throws Throwable {
long start = System.currentTimeMillis();
Object result = joinPoint.proceed();
long executionTime = System.currentTimeMillis() - start;
log.info("Method name : {} , executed in {} ms", joinPoint.getSignature(), executionTime);
return result;
}
}로그인 시나리오 (로컬에서 테스트 진행) - k6 사용
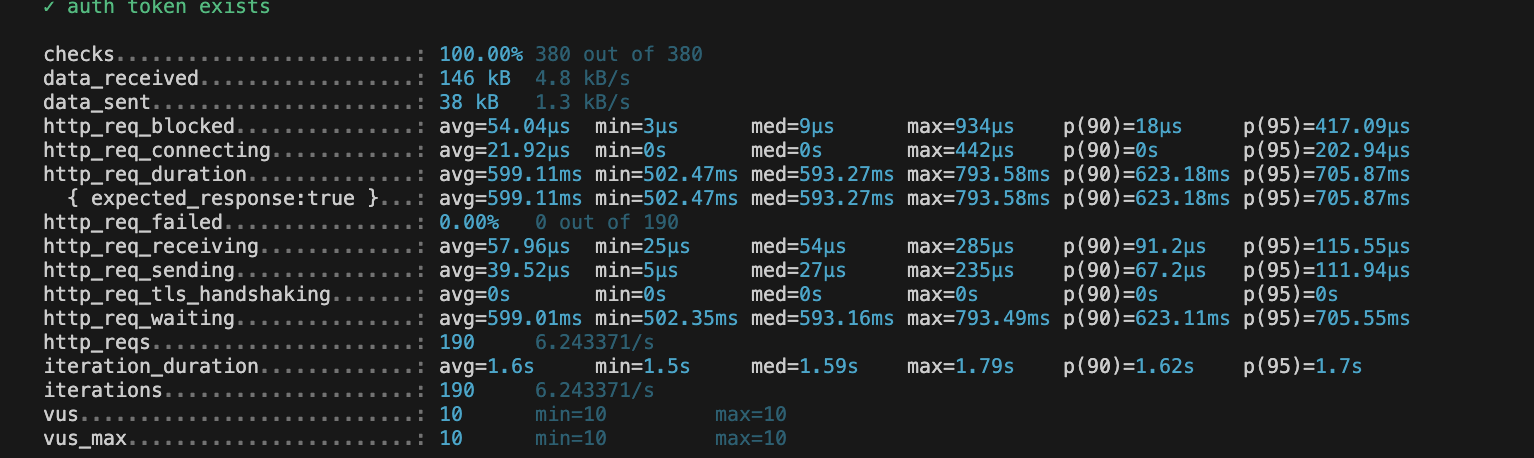
- 10개의 동시요청을 19번 반복 (총 190번의 요청)
- 로컬에서 진행하였기 때문에 네트워크 병목은 거의 없다.
- p(95) 를 기준으로 705ms 정도 나오는것을 확인할 수 있었다.
우선 로그인 시나리오는 다음과 같다.
POST localhost:8080/login -> EmailPasswordAuthenticationFilter -> CustomAuthenticationProvider -> MemberDetailsService.loadUserByUsername(조회 쿼리) -> AuthSuccessHandler -> authService.findByEmail(조회 쿼리) -> authRepository.save(쓰기 쿼리)
병목지점 찾기
- 병목 지점을 찾기위해서 ExecutionTimeAspect 로 로깅 + Intellij Profiler 를 활용하여 실행시간 추가 로깅
로깅을 해본 결과 BCryptPasswordEncoder.matches 메서드에서 전체 실행시간의 94프로를 차지하고 있는 것을 확인할 수 있었다.


어플리케이션 설계상 해당 부분은 남겨두고 먼저 해결할 수 있는 부분에 집중하기로 했다.
해당 부분 병목에 비하면 작은 수준이지만 문제가 있는 부분은 refreshToken 저장을 위한 조회와 저장쿼리를 날린다는 것인데 즉
유저 n명당 auth테이블에 접근하는 쿼리가 2개 발생하게 된다. 즉 n+1 문제가 발생하게 된다.
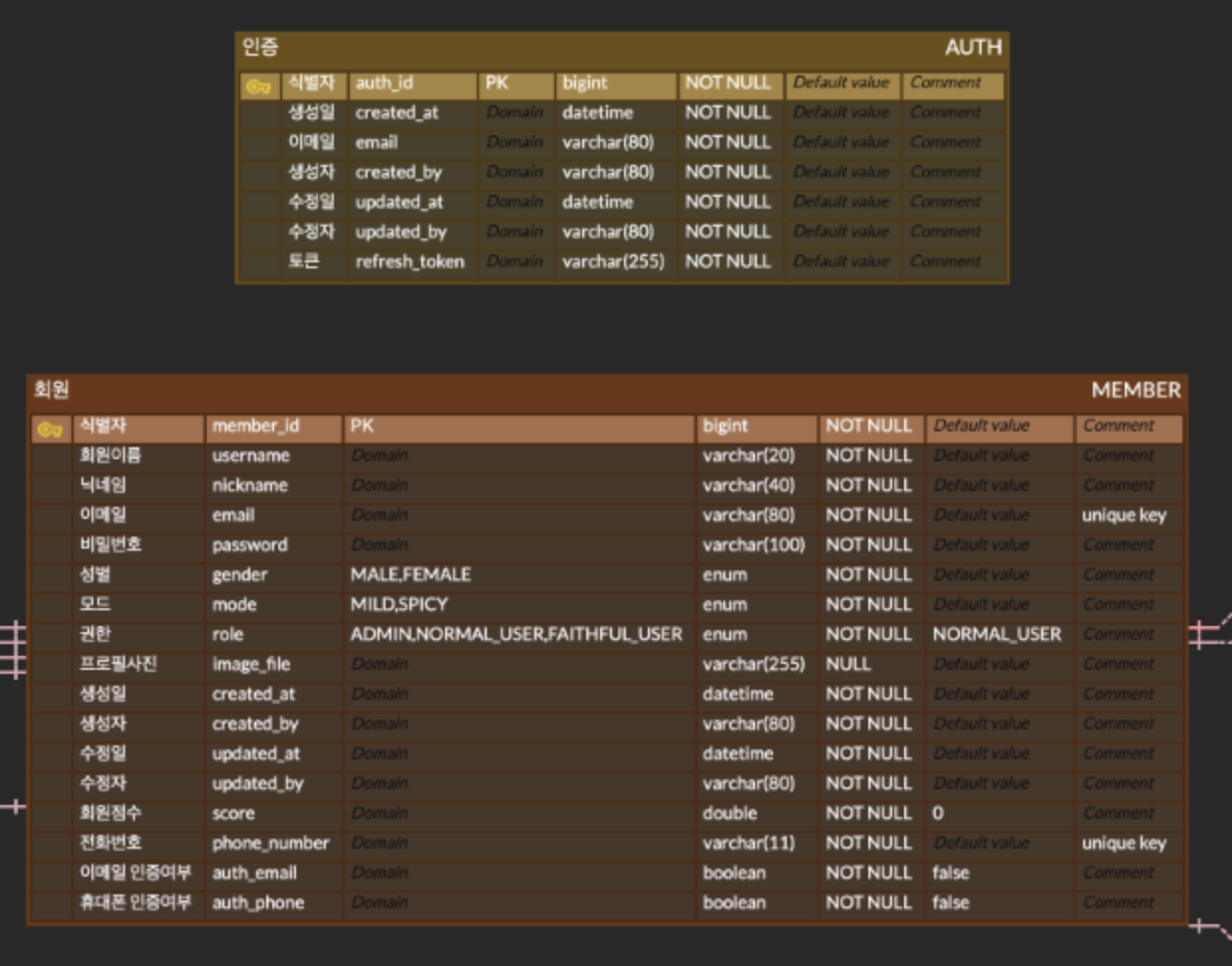
이 부분을 해결하기 위해 고려한 방식은 위 테이블 구조처럼 물리적으로는 분리되어 있는 테이블 두개를 조인해서 Auth,Member를 필드로 갖는 Dto를 하나 만들어서 두개를 동시에 조회해서 사용하면 어떨까 라고 생각했는데 애초에 인증절차를 진행하는 부분과 , 인증 테이블에 인증객체를 넣어주는 방식이 분리되어 작동 하기 때문에 같은 트랜잭션에 소속될 수 없고 결국 조회쿼리를 한번 더 날려야하는 구조였기에 맞지 않다고 생각을 했다.
RefreshToken 자체가 유저가 로그인 할 때마다 매번 갱신되는 데이터이기도 하고 재인증 과정에서 자주 사용되는 데이터라는 점, saveOrUpdate시 조회,저장쿼리 모두 날리는 상황에서 하나의 쿼리로 처리할 수 있다는 부분에서 Auth 정보를 메모리에 저장하여 사용하는 방식을 택했다. 레디스 사용을 위한 구조 개선에 대한 코드는 본 포스트에서는 다루지 않겠다.

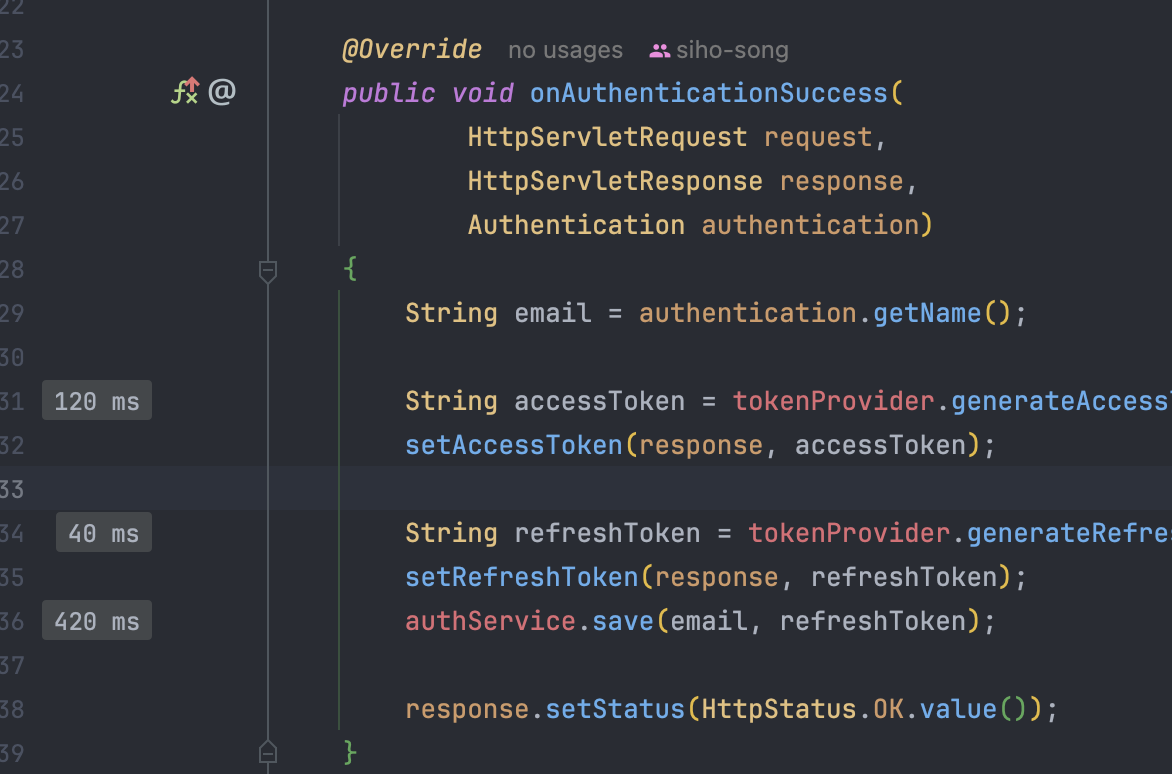
Redis 적용전 (rps)
730ms (10개 동시요청 19번 반복 )
Redis 적용후
authService.save : 420ms (10개 동시요청 19번 반복)
위 케이스에서는 유저 1000명에 대해서 테스트를 진행했다. 드라마틱한 개선효과는 아니지만 아주 .. 약간의 개선은 이루어 졌지만 미미하다고 생각이 든다. 하지만 유저테이블에 인덱스가 걸려있지 않은 상황이고 유저의 수가 10만 -> 100만 혹은 더 많은 유저가 존재한다고 생각한다면 유저테이블을 풀스캔해야하고 선형적으로 조회 시간이 증가할 것이고 더 큰 개선효과가 생기지 않을까 생각해본다.
소규모 어플리케이션의 유저수를 기준으로 봤을 때는 성능 개선보다는 세션 저장을 위한 구조적인 이점을 가져수 있었다는 점이 더 크지 않을까
실질적으로 문제를 해결하기 위해서는 bcrypt의 matches 연산이 cpu 집약적인 연산이기 때문에 cpu 코어를 늘려 가용가능한 쓰레드 수를 늘리거나 보다 실용적인 방법으로는 서버를 scale-out 하는 방법이 있을 것 같다.
'Spring > 개인 프로젝트' 카테고리의 다른 글
| [성능 최적화] 일정조회 성능개선 (Feat. 인덱스) (0) | 2025.03.08 |
|---|---|
| [멀티 모듈화] 1. 멀티 모듈화의 이유 및 Gradle 세팅 (0) | 2025.02.23 |
| SSE + Redis Pub/Sub, Scale-out을 고려한 알람 시스템 구현 (0) | 2024.12.19 |
| 개발 서버 더미 데이터 추가 (1) | 2024.12.01 |