시스템 환경
Hardware Resources : CPU 8 Core, 4GB Memory
Test Tool : k6
Mornitoring Tool : Prometheus , Grafana
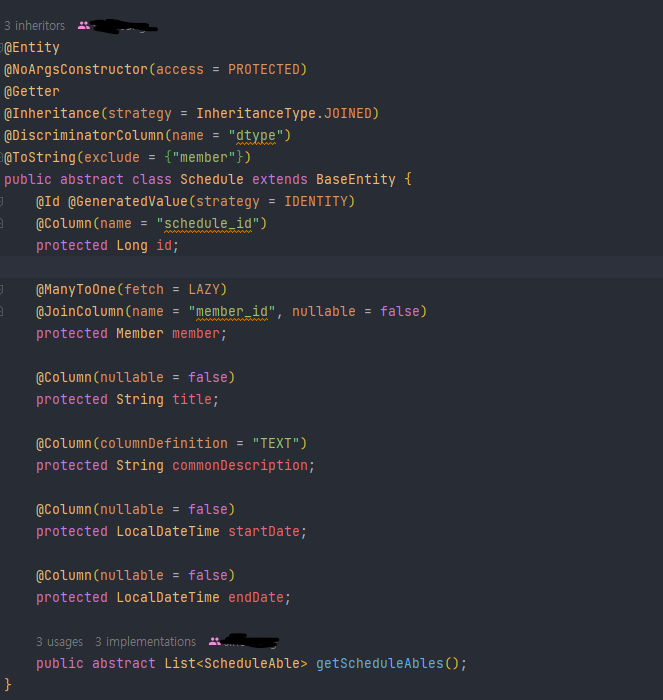
Application : Spring Boot Application (Boot Version 3.2.5)
DB : Mysql
모니터링 환경
- K6 에서 조금 더 세세한 정보를 수집하기 위해서 InfluxDB + Grafana 연동
- SpringBoot Application 관련 메트릭 정보 수집을 위해 SpringBoot Actuator + Prometheus + Grafana 연동
- 시스템 메트릭 수집을 위해 Node Exporter + Prometheus + Grafana 연동
테스트 시나리오
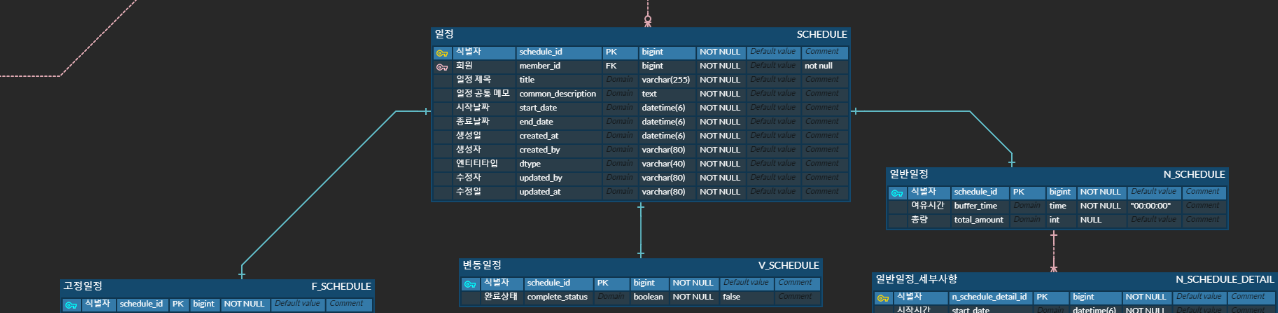
- 약 40만개의 일정 데이터로 테스트를 진행했습니다. (일정 = 고정일정 + 변동일정 + 일반일정 )
본 테스트에서는 일반일정 데이터는 거의 추가하지 않고 (약 1만개) 고정일정 + 변동일정 데이터만 추가하여 진행했다.
- 일정관리 웹 서비스로써 일정조회에 대한 요청이 대다수 일 것이라고 판단하고 테스트를 진행했다.
- 테스트 시나리오는 일정 조회 Api 에 Virtual User를 활용하여 Get 요청을 보내 유저의 최근 3개월 내 모든 일정을 조회한다.
- 응답시간 목표를 95% 이상의 요청은 500ms 이하로 설정했다.
- CPU사용량, Memory 사용량 P95~P99 응답시간, TPS , 에러율 등을 고려하여 부하를 판단했다.
- IntelliJ Profiler , (디비 수준에서의 병목 쿼리 파악하기.) 병목 지점을 파악했다.
1. 성능 테스트
먼저 시스템의 임계점을 분석하기 위해 스트레스 테스트를 진행했고, 0명의 가상 유저부터 70명의 가상유저까지 점차적으로 늘리는 Ramping-vus 방식으로 테스트를 진행했다.

Virtual User의 수가 약 40명 정도 부근에 가까워 졌을때 부터 지연율이 높아졌으며 p95 기준 응답시간 목표인 500ms 보다 더 늦은약 500ms~1s 사이의 응답 시간을 보여 주었다. 그렇기 때문에 해당 지점을 임계치를 초과한 지점으로 보고 45Vus 를 유지한 상태에서 부하테스트를 진행하였고 결과 역시나 성능이 좋지 않음을 확인할 수 있었다.
2. 병목 지점 파악
Spring Profiler
부하 테스트 이후 먼저 Spring profiler를 통해 실행결과를 확인했다.
다음은 일정 조회시 조회 시나리오에 맞게 분석한 결과이다.
- 1. memberRepository.find - 단순 조회


- 2. vScheduleRepository.find - 단순 조회
- 3. fScheduleDetailRepository.find - 1번의 left join
- 4. nScheduleDetailRepository.find - 1번의 left join


위 결과에서 확인할 수 있는건 cpu 사용시간에 비해 전체 실행시간이 훨씬 길다는 것을 확인할 수 있었다. 즉 전체 실행 시간 대비 CPU Time이 매우 적으므로, 대부분의 시간은 I/O 대기 시간이라고 볼 수 있다.

추가적으로 Hikary CP 의 커넥션을 확인해 보면 모든 커넥션이 사용중이고, 평균 9개에서 최대 15개의 요청이 커넥션을 얻기 위해 대기중이라는 것을 확실히 확인할 수 있었다. 그렇기 때문에 DB에서의 병목을 파악해서 위 문제를 해결하고자 했고 쿼리 실행 계획을 활용해서 위 시나리오들의 각 쿼리들에 대해서 분석해보았다.
1. EXPLAIN ANALYZE SELECT * FROM member WHERE email = 'normal1@example.com';
Res) -> Rows fetched before execution (cost=0..0 rows=1) (actual time=251e-6..293e-6 rows=1 loops=1)
2. EXPLAIN ANALYZE SELECT * FROM v_schedule WHERE start_date_time >= '2025-01-01 00:00:00' AND end_date_time <= '2025-03-08 23:59:59' AND created_by = 'normal1@example.com'
Result) Filter: ((v_schedule.created_by = 'normal1@example.com') and (v_schedule.start_date_time >= TIMESTAMP'2025-01-01 00:00:00') and (v_schedule.end_date_time <= TIMESTAMP'2025-03-08 23:59:59')) (cost=20367 rows=2199) (actual time=0.229..126 rows=2 loops=1)
-> Table scan on v_schedule (cost=20367 rows=197977) (actual time=0.209..108 rows=199999 loops=1)
3. EXPLAIN ANALYZE SELECT * FROM f_schedule_detail fd left outer join f_schedule f on f.f_schedule_id = fd.f_schedule_id WHERE fd.start_date_time >= '2025-01-01 00:00:00' AND fd.end_date_time <= '2025-03-08 23:59:59' AND fd.created_by = 'normal1@example.com'
Res) Nested loop left join (cost=18427 rows=1923) (actual time=0.213..117 rows=35 loops=1)
-> Filter: ((fd.created_by = 'normal1@example.com') and (fd.start_date_time >= TIMESTAMP'2025-01-01 00:00:00') and (fd.end_date_time <= TIMESTAMP'2025-03-08 23:59:59')) (cost=17754 rows=1923) (actual time=0.124..117 rows=35 loops=1)
-> Table scan on fd (cost=17754 rows=173117) (actual time=0.114..99.2 rows=175000 loops=1)
-> Single-row index lookup on f using PRIMARY (f_schedule_id=fd.f_schedule_id) (cost=0.25 rows=1) (actual time=0.00294..0.00298 rows=1 loops=35)
4. EXPLAIN ANALYZE SELECT * FROM n_schedule_detail nd left outer join n_schedule n on n.n_schedule_id = nd.n_schedule_id WHERE nd.start_date_time >= '2025-01-01 00:00:00' AND nd.end_date_time <= '2025-03-08 23:59:59' AND nd.created_by = 'normal1@example.com'
Res) -> Nested loop left join (cost=666 rows=64.8) (actual time=9.46..9.46 rows=0 loops=1)
-> Filter: ((nd.created_by = 'normal1@example.com') and (nd.start_date_time >= TIMESTAMP'2025-01-01 00:00:00') and (nd.end_date_time <= TIMESTAMP'2025-03-08 23:59:59')) (cost=607 rows=64.8) (actual time=9.46..9.46 rows=0 loops=1)
-> Table scan on nd (cost=607 rows=5829) (actual time=0.107..8.11 rows=5963 loops=1)
-> Single-row index lookup on n using PRIMARY (n_schedule_id=nd.n_schedule_id) (cost=0.814 rows=1) (never executed)
1번의 경우 이미 유니크 키로 지정되어있는 유저의 email을 기준으로 index가 생성되어 있기때문에 매우 빠른시간내에 조회하고 있다는 점을 확인할 수 있었다.
2번,3번,4번 같은 경우는 join 대상이 되는 테이블같은 경우는 PK 인덱스를 통해 빠르게 조회가 되는 것을 확인할 수 있지만 자기 테이블에 대해서는 인덱스 없이 Full-Scan 하고 있었기 때문에 적절한 인덱스를 생성하여 조회 시간을 감축시킬 수 있다고 생각했다.
각 일정들의 조회를 동반하는 쿼리 중 id로 조회하는걸 제외하면 start_date_time, created_by를 기준으로 조회를 하는 경우가 대다수이고 거의 대부분의 시나리오에서 위와 같은 모든 일정을 start_date_time, end_date_time 사이의 일정을 조회하기 때문에start_date_time, end_date_time,created_by 에 대해서 복합 인덱스를 생성하는 것이 좋을 것이라 판단했다.
3. Index 적용
인덱스를 설계한다고 했을 때, start_date_time,end_date_time,created_by 순으로 인덱스를 설계한다고 가정하면 첫 번째 컬럼이 범위 검색이므로 인덱스가 제대로 작동하지 않을 수 있다고 생각했고 실제로도 그랬다. 따라서 (created_by, start_date_time, end_date_time) 의 복합 인덱스를 생성했다.
고정일정 인덱스 적용 후
Nested loop left join (cost=22.5 rows=35) (actual time=0.14..0.311 rows=35 loops=1)
-> Index range scan on fd using f_detail_created_start_end_idx over (created_by = 'normal1@example.com' AND '2025-01-01 00:00:00' <= start_date_time), with index condition: ((fd.created_by = 'normal1@example.com') and (fd.start_date_time >= TIMESTAMP'2025-01-01 00:00:00') and (fd.end_date_time <= TIMESTAMP'2025-03-08 23:59:59')) (cost=16 rows=35) (actual time=0.0772..0.223 rows=35 loops=1)
-> Single-row index lookup on f using PRIMARY (f_schedule_id=fd.f_schedule_id) (cost=0.259 rows=1) (actual time=0.00219..0.00223 rows=1 loops=35)
변동일정 인덱스 적용 후
Index range scan on v_schedule using v_schedule_created_start_end_idx over (created_by = 'normal1@example.com' AND '2025-01-01 00:00:00' <= start_date_time <= '2025-03-08 23:59:59'), with index condition: ((v_schedule.created_by = 'normal1@example.com') and (v_schedule.start_date_time between '2025-01-01 00:00:00' and '2025-03-08 23:59:59')) (cost=1.16 rows=2) (actual time=0.0883..0.112 rows=2 loops=1)
일반일정 인덱스 적용 후
Nested loop left join (cost=1.08 rows=1) (actual time=0.0591..0.0591 rows=0 loops=1)
-> Index range scan on nd using n_detail_created_start_end_idx over (created_by = 'normal1@example.com' AND '2025-01-01 00:00:00' <= start_date_time), with index condition: ((nd.created_by = 'normal1@example.com') and (nd.start_date_time >= TIMESTAMP'2025-01-01 00:00:00') and (nd.end_date_time <= TIMESTAMP'2025-03-08 23:59:59')) (cost=0.71 rows=1) (actual time=0.0581..0.0581 rows=0 loops=1)
-> Single-row index lookup on n using PRIMARY (n_schedule_id=nd.n_schedule_id) (cost=1.11 rows=1) (never executed)
4. Index 적용 후 비교
Index 적용 후 적용 전과 같은 조건으로 테스트를 진행했다.
Spring Profiler 로 비교

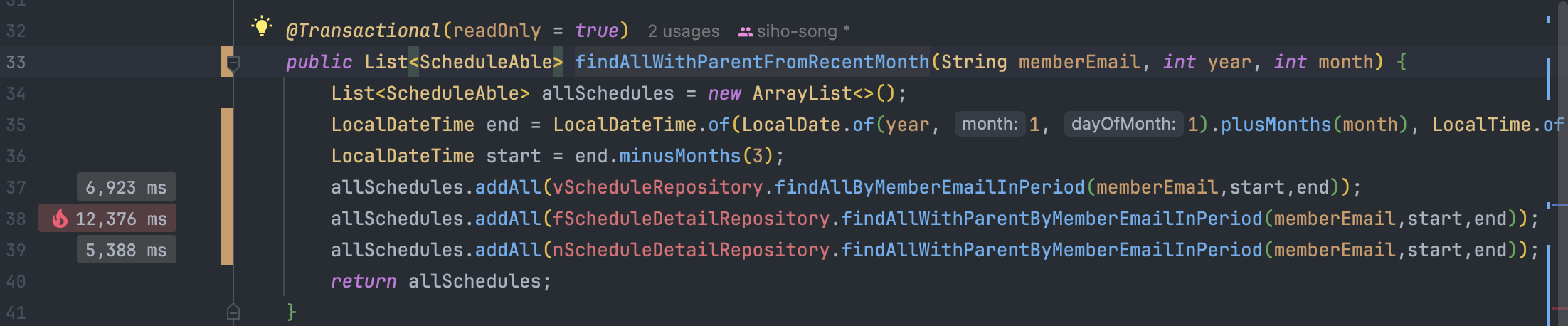
Index 적용 전과 CPU 사용시간은 크게 다르지 않은 것을 확인할 수 있다. 그리고 전체 실행시간은 약 180만 ms -> 약 6만 ms 로 감축된 것을 확인할 수 있다.
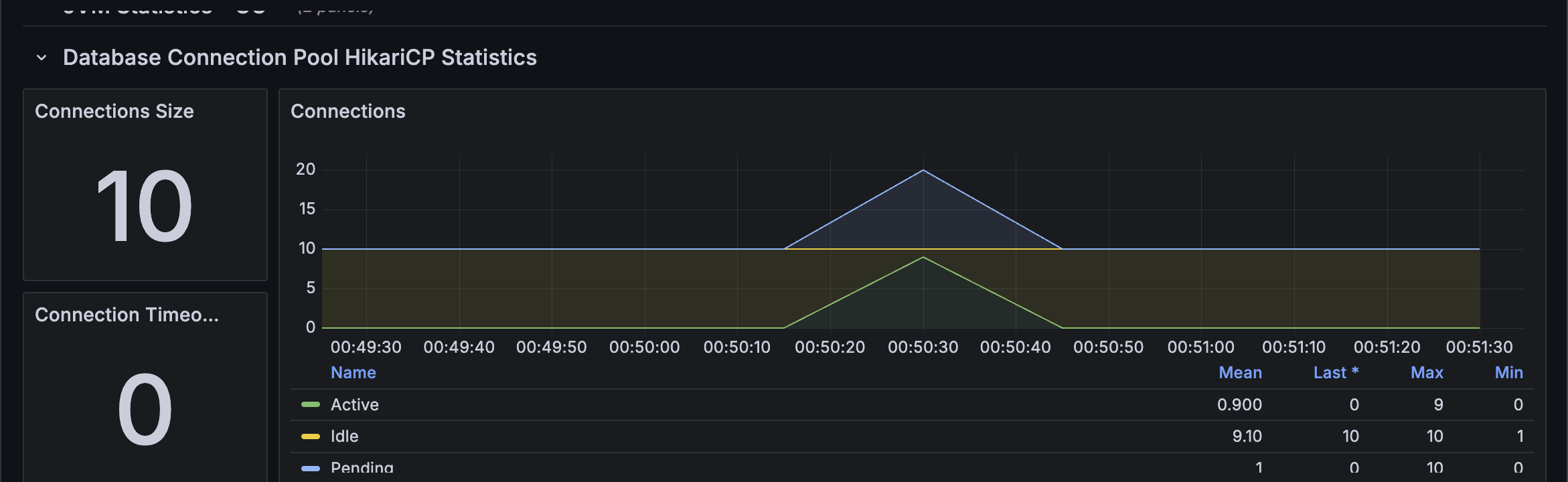
HikariCP의 Connection 사용 또한 처음 동시접속이 있었을때 pending 상태 이후로는 안정적으로 처리하는 것을 확인할 수 있었다.
또한 Grafana를 통해 확인해보면 req_duration (p95) 기준으로 4.94(4940ms)초에서 57.10ms 로 약 86배 줄어든 것을 확인할 수 있다.
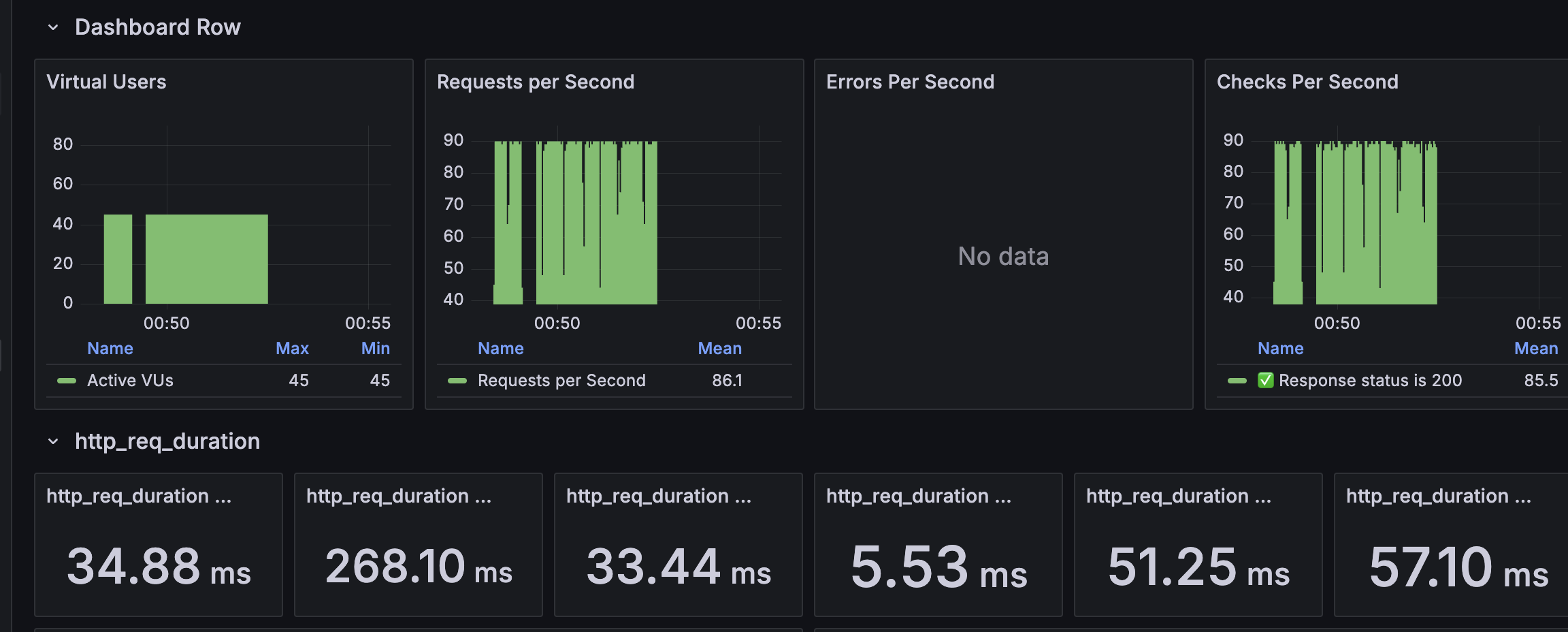
위와 같이 성능 개선을 확인하고 Virture User의 수를 늘려서 추가적으로 스트레스 테스트를 진행해보았다.
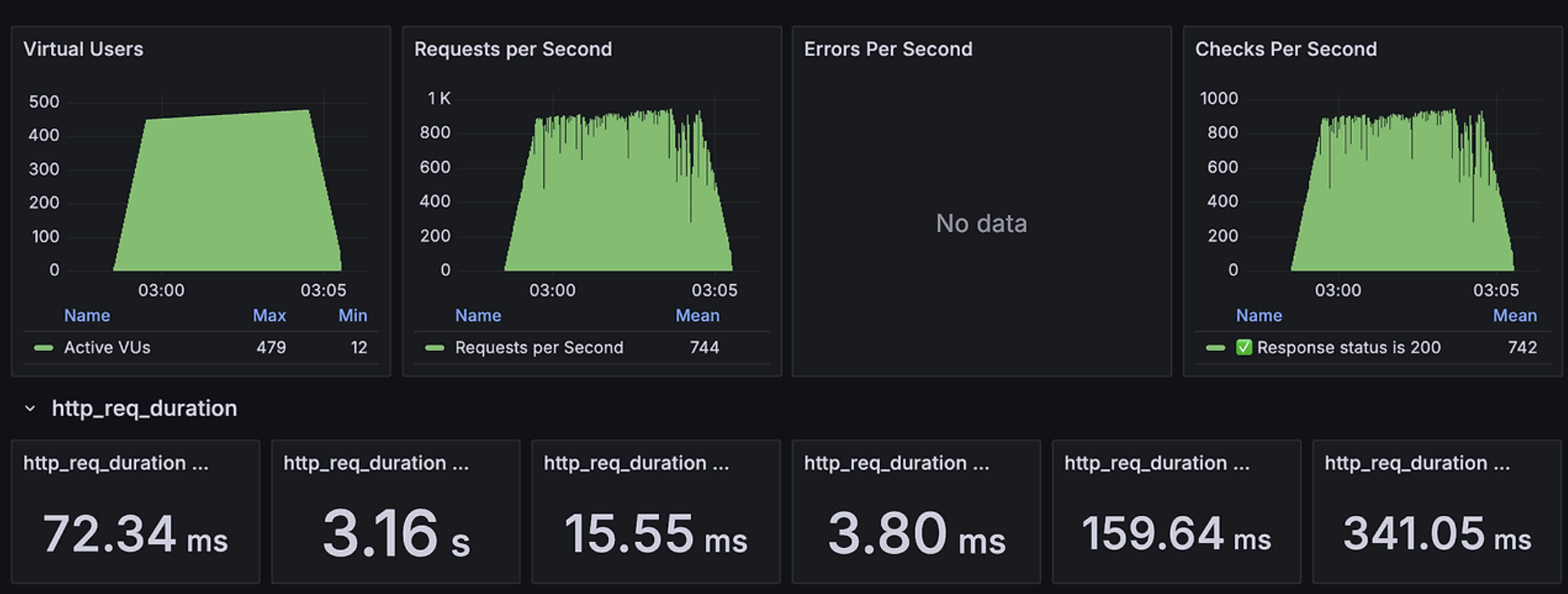
RPS(Requests Per Seconds)가 23에서 744로 약 32배 증가하여 처리량이 크게 개선되었음을 확인할 수 있다. 추가적인 개선은 시스템의 메모리와 CPU 사용량을 모니터링하고 적절량 만큼의 HikariCP 의 max_pool_size를 늘린다면 추가적인 성능 개선이 가능 할 것 같 DB 레벨에서의 지연이 어플리케이션에 얼마나 큰 영향을 미치는지 실감할 수 있었다.
'Spring > 개인 프로젝트' 카테고리의 다른 글
| [멀티 모듈화] 1. 멀티 모듈화의 이유 및 Gradle 세팅 (0) | 2025.02.23 |
|---|---|
| SSE + Redis Pub/Sub, Scale-out을 고려한 알람 시스템 구현 (0) | 2024.12.19 |
| 로그인 성능 개선 (Feat. Redis) (0) | 2024.12.02 |
| 개발 서버 더미 데이터 추가 (1) | 2024.12.01 |